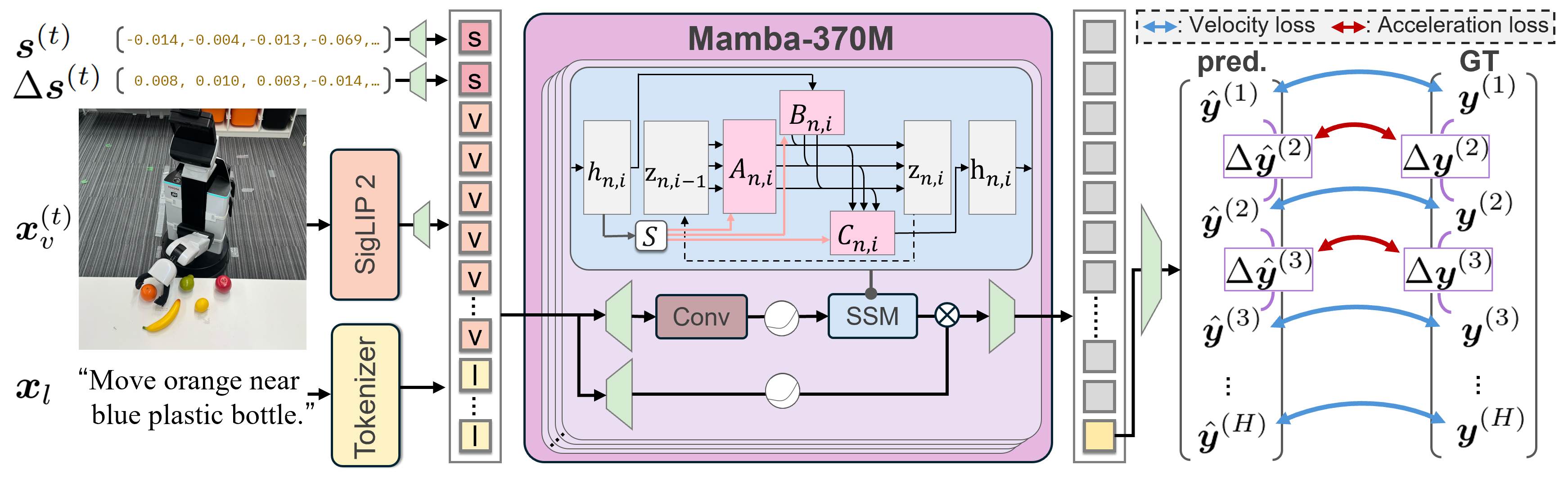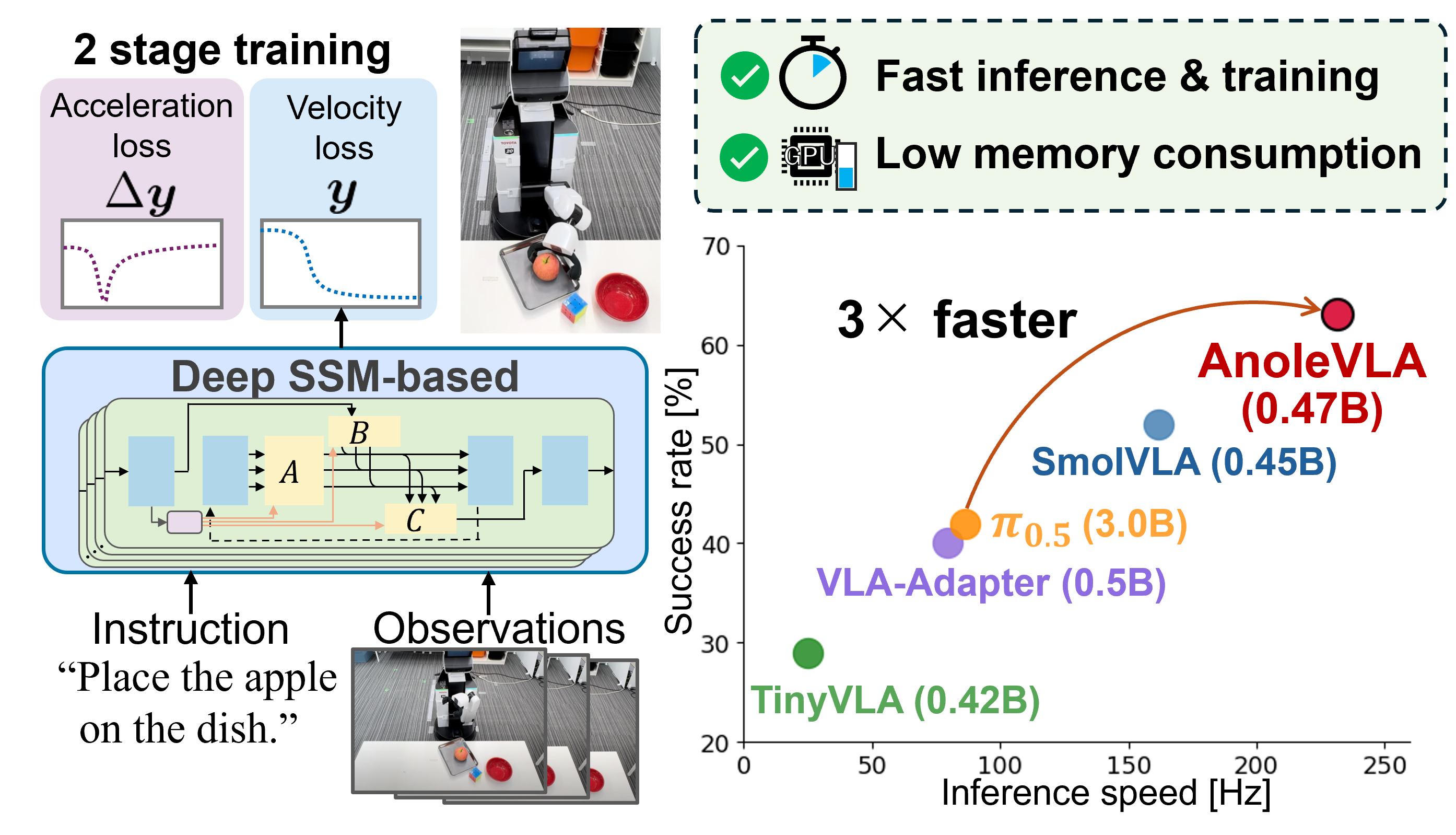
Fig. 1: Overview of AnoleVLA and real-world performance. (Left) Our deep SSM backbone processes language instructions and robot observations to generate trajectories, leveraging a two-stage training strategy with the acceleration loss for smooth control. (Right) Physical experiment results. The x and y-axes represent inference speed and the average success rate, respectively. AnoleVLA achieved the highest overall success rate. Notably, compared to $\pi_{0.5}$, AnoleVLA not only yields superior task performance but also demonstrates an inference speed approximately three times faster.